Benchmark Overview
DeskCraft combines a three-level difficulty taxonomy, a composable human-in-the-loop protocol, and broad coverage of professional desktop software.
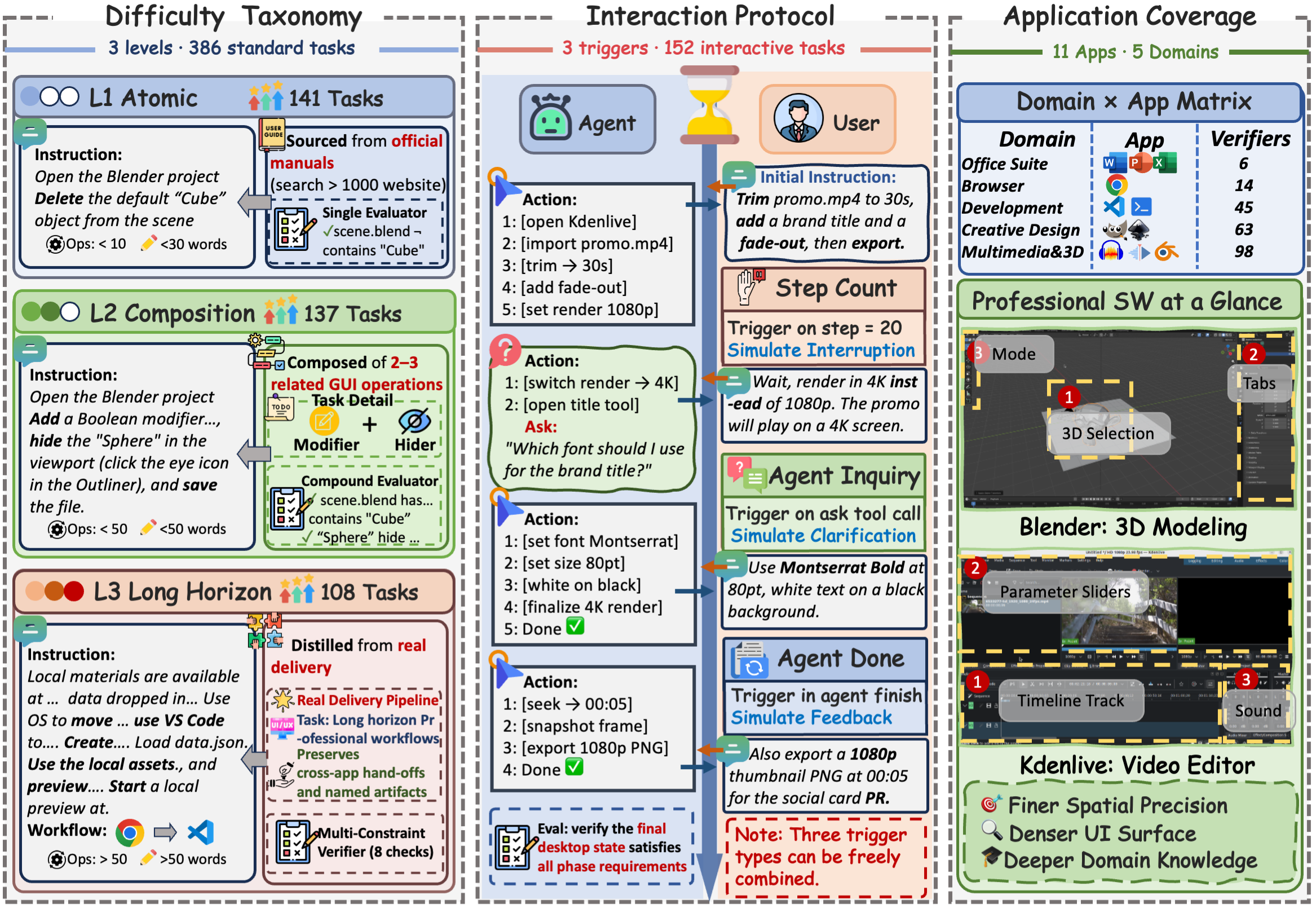
Figure 1. Overview of DeskCraft. Left: 386 standard tasks stratified into L1 atomic, L2 compositional, and L3 long horizon levels. Middle: 152 interactive tasks driven by three composable triggers. Right: 11 applications across 5 domains, including professional software such as Blender and Kdenlive.
L1 / L2 / L3 Taxonomy
Tasks progress from atomic GUI operations (L1) to compositional multi-step actions (L2) and long-horizon delivery workflows distilled from real professional scenarios (L3).
Human-in-the-Loop Protocol
Interactive tasks evolve through deterministic phase triggers — agent clarification, user interruption, and post-completion feedback — enabling reproducible collaboration.
Execution-Based Verification
Programmatic evaluators inspect final desktop state, project files, exported artifacts, browser state, media metadata, and structured documents — no subjective manual scoring.